From time to time, you need to work with data which is living somewhere online so let’s have a look on how Power Query can help you. I will be describing various scenarios which I personally tested multiple times.
***Tip: Have a question? Ask in the comment section below or in this Facebook group. You can also sign up for our free newsletter.***
***Do you feel like you need more help? We can help you with PPC Automation and/or with your reporting under our new project MythicalReports.com here.***
Predefined “From Web” Option as Data Source
Even if you just started with Power Query, you must have noticed, there is “From Web” data source. When you select choose “From Web” as data source, a window will open:

It’s no surprise that Power Query expects a URL which is then crawled for information. So let’s try www.seznam.cz. Enter the URL and hit “OK”. New window will load:

Hmm, that does not look nice. This does not tell us anything because the page does not contain any visible tables. Hit Cancel and proceed to the next example.
Loading Web Tables
When working with a URL & From Web function, Power Query still expects to find a table on the page you want to crawl. So instead of www.seznam.cz, let’s try https://en.wikipedia.org/wiki/List_of_sovereign_states:
(Click the animation to see it in fullscreen mode)

In this case, the situation looks more positive. Because the wikipedia page has clearly visible tables (unlike Czech Google copy seznam.cz), Power Query can see them as well and as a result, you can easily load them and use as data source. From now on, you can make the same transformations as you would do with a file stored locally on your PC.
Loading Online Files
So what if you want to load e.g. a CSV file stored on a URL? Let’s work with the CSV file stored on this page: https://support.spatialkey.com/spatialkey-sample-csv-data/. The CSV file address is: http://samplecsvs.s3.amazonaws.com/Sacramentorealestatetransactions.csv (Real estate transactions).
This what will happen:
(Click the animation to see it in fullscreen mode)

Magic. The Online CSV file is now loaded to Power Query. You only need to refresh your query when the file changes 🙂 The important thing in this example is understanding what really happened. So let’s have a look and the actual step “Source”:

You can see that Power Query automatically started with Web.Contents() function which just downloads the “object” and then it opened the object with Csv.Document() function because it automatically detected the CSV file format. The only thing I changed is addition of line breaks. So the takeway here is that Web.Contents() is similar to File.Contents() function. Power Query uses File.Contents for accessing local files while Web.Contents is used for accessing online files. Once the file is “accessed”, another function needs to be used to open the object depending on the file type (Csv.Document, Excel.Workbook, Lines.FromBinary…). Knowing this approach basically lets you open the same file types no matter whether they are stored online or offline. You sometimes need to edit the formula manually when Power Query struggles to guess the file type of online file.
Another important note is that the online files should be accessible publicly without any requirements for login. Power Query supports some limited login mechanisms but none of them have been useful during my testing of “locked” files.
Loading Google Sheets
Working with Google Sheets is covered in this article.
Loading XML Feeds as Data Source
If you are working for an e-tailer, all sorts of feeds are your daily bread. It’s no surprise now that you can use XML feed as data source. All you need to have is the URL. The rest is that same like in the previous examples. In this example, we will use this feed https://www.w3schools.com/xml/cd_catalog.xml:
(Click the animation to see it in fullscreen mode)

We can see that Power Query used Web.Contents() again and then on the top of that, Xml.Tables() function was used.
Crawling Sitemaps to Spy on Your Competition
Sitemaps are extremely valuable source of information because the usually contain all the URLs for a given domain of your choice so Google robot can index all the URLs. However, sitemaps can be crawled by Power Query as well 🙂 Assume you want to figure out how many product pages does www.alza.cz have (it’s a Czech clone of Amazon).
First, you need to locate the sitemap file by doing some old school Googling in your regular browser:
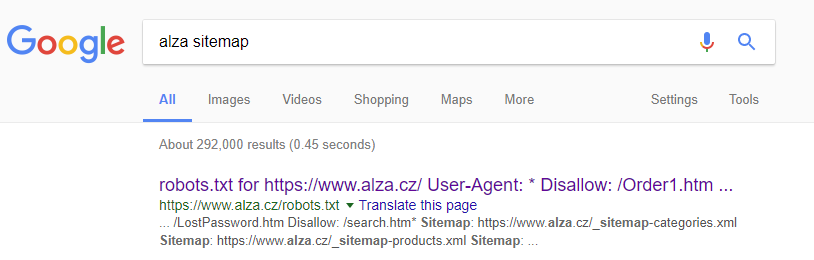
It takes exactly 1 search to find the sitemap URL. The URL is: https://www.alza.cz/robots.txt. Open the URL and you will see:

Of course, we are interested in …products.xml. So lets deploy Power Query:
Note that this procedure is for more advanced users but I am sure everyone can see at least some logic there. Also note, that I cut out “waiting parts” from the video. Overall, the entire process took me 5 minutes from start to finish in real life.
So what is the answer to my question? How many products does Alza.cz have? Well, at the time of writing, Alza.cz had around 168,000 products on their website.
Loading Source Code of a Web Page
Lets re-crawl our friends at Seznam.cz and load page source code. You might be asking why the hell you should load source code? Here are 2 common examples:
- To find a specific piece of information in the code
- To find more URLs for subsequent crawling.
As usual, you need to start with Web.Contents() function. Then you need to use handy function called “Lines.FromBinary()”.
The final function looks like: Lines.FromBinary(Web.Contents(“www.seznam.cz”)). In this case, you want to start with “Blank query” and insert the function as the first step:
(Click the animation to see it in fullscreen mode)

That wasn’t that hard either, was it? 🙂
Using Power Query to Do API Calls
You can use Power Query download data via API calls. These queries would be classified as “advanced” and are not so easy to construct because you need little bit of coding knowledge.
The key piece in the puzzle is “From Web” data source switched to “Advanced” mode:

You can see that there is way more stuff to fill in. You also need to know background of the system where you are pulling the data from – especially, you need to know how to construct the HTTP request. You also need to have some sort of “api key” which is basically used as login.
Again, this is more for advanced users and is not worth going into too much details because settings for every system would be different. Just keep in mind that API calls are possible in Power Query.
Conclusion
You can see that there are so many use cases when Power Query can help you getting data from Web and detailed understanding the logic of Web.Contents + the “opening file type” function can make your life much easier.
The sample file created during this exercise is here.
***Tip: Have a question? Ask in the comment section below or in this Facebook group. You can also sign up for our free newsletter.***
***Do you feel like you need more help? We can help you with PPC Automation and/or with your reporting under our new project MythicalReports.com here.***
I really would wish to thank you for your in depth guidance on how to retrieve unstructured data from the web. Yesterday I studied the problem for some long hours und couldn’t figure it out.
Trying to figure out how to iterate through a set of ids in the web search url field #2 in order to retrieve specific api records and then join those results into a single table.
ids query: ids = (guid1, guid2, guid3…)
url query: http://webserver.local:9000/api/group/thing/{ids}/info
To return a table of things on rows with info split into columns from the set of urls for all ids.
Just create a table of specific URLs via merge feature (“multiply” X ids against your 1 URL with placeholder), then add a column calling all those functional URLs…?
thanks for the information, there will be a hug scope for Power BI and future for it. Top Job Placement Consultancy Power BI in Indore