Problem
A customer needed to quickly understand the most common technical issues affecting particular car models on the US market. While NHTSA publishes these issues on daily basis for each car model, it’s not user friendly to work with. The requirement was to simply “ask” via email while providing the car model and get a reply back with the outcome via email again.
The main challenge I was facing was that the car models were manually entered by human beings. This means that a person can enter e.g. “2021 Chevy Slveraaado” (including jargon, typos, etc.) and the automation needs to convert this input to “2021 Chevrolet Silverado” because NHTSA “issues” dataset only knows “2021 Chevrolet Silverado” and not “2021 Chevy Slveraaado”.
So before I could look up any issues, I needed to normalize the human inputs. Once the process passes through normalization, the Make scenario also generates a summary of known issues for the particular vehicle and also a suggestion for a Meta Ads ad mentioning those issues.
Solution
We are living in the AI area now so why not to use AI to perform the loose match search? The final Make scenario is not too complicated in this case, what was more important in this problem was to come up with a high level design to solve the problem and this is it:
- At first, I am comparing the human input against the list of models hosted in BigQuery. I run a simple SQL query looking for exact match to determine whether OpenAI is needed for normalization.
- If no exact match is found, then I ask OpenAI to find the closest match based on the provided inputs.
- If exact match is found, I take the unchanged human and proceed further.
- I generate the summary of known issues (issues are provided by NHTSA which is publishing a daily file of new complaints from US consumers).
- I generate a few suggestions for Meta Ads ads.
Scenarios and Outcomes
Workers can easily invoke the workflow by sending an email to a unique email address provided by Make while specifying the car model in the subject. The outcome is an email that is send back to the original sender with the summary of issues and suggestions of ads.
This is the scenario:
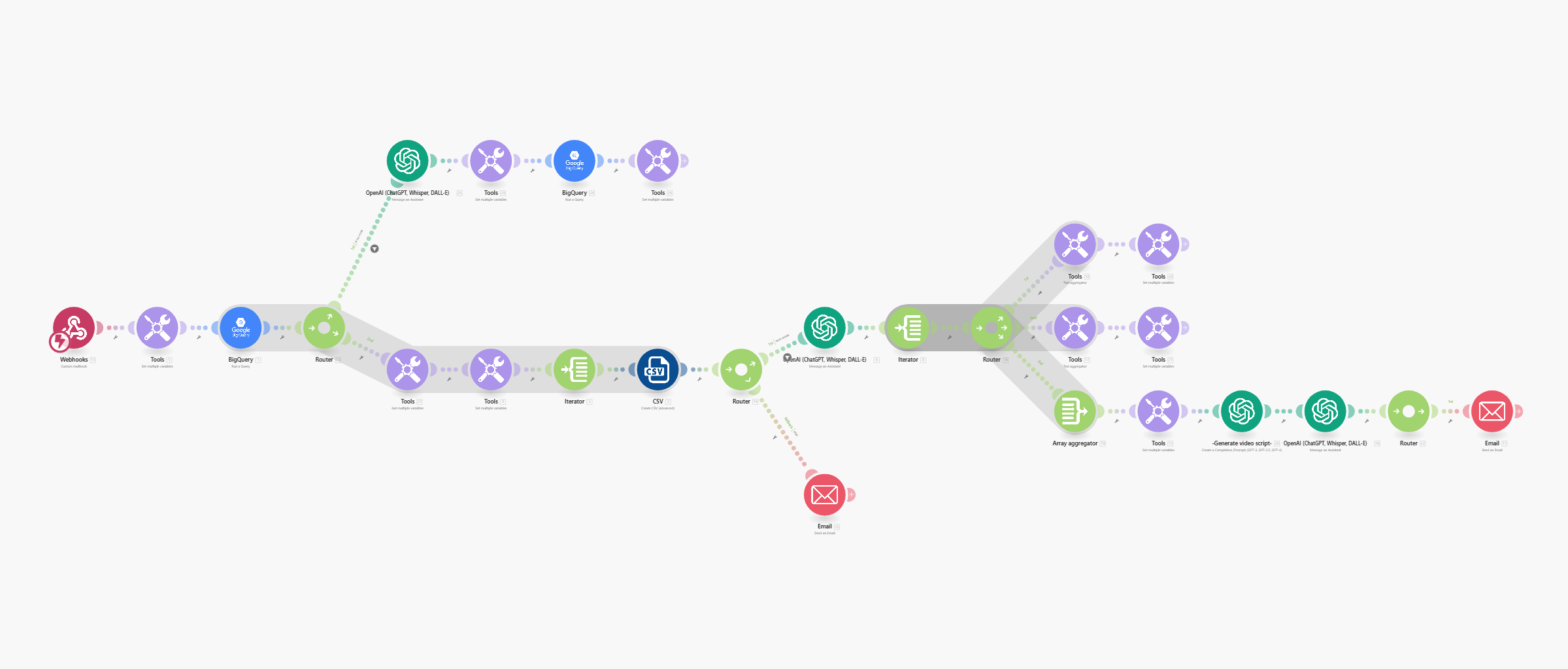
When it comes to OpenAI steps, I am mostly using “Message an Assistant” modules. To perform the loose match search, I’ve created an assistant that is ingesting the human input and running a search through a vector store file (containing all the models) stored in OpenAI. Of course, you need to deliver the file to OpenAI somehow and for that, I’ve created another scenario which runs daily:
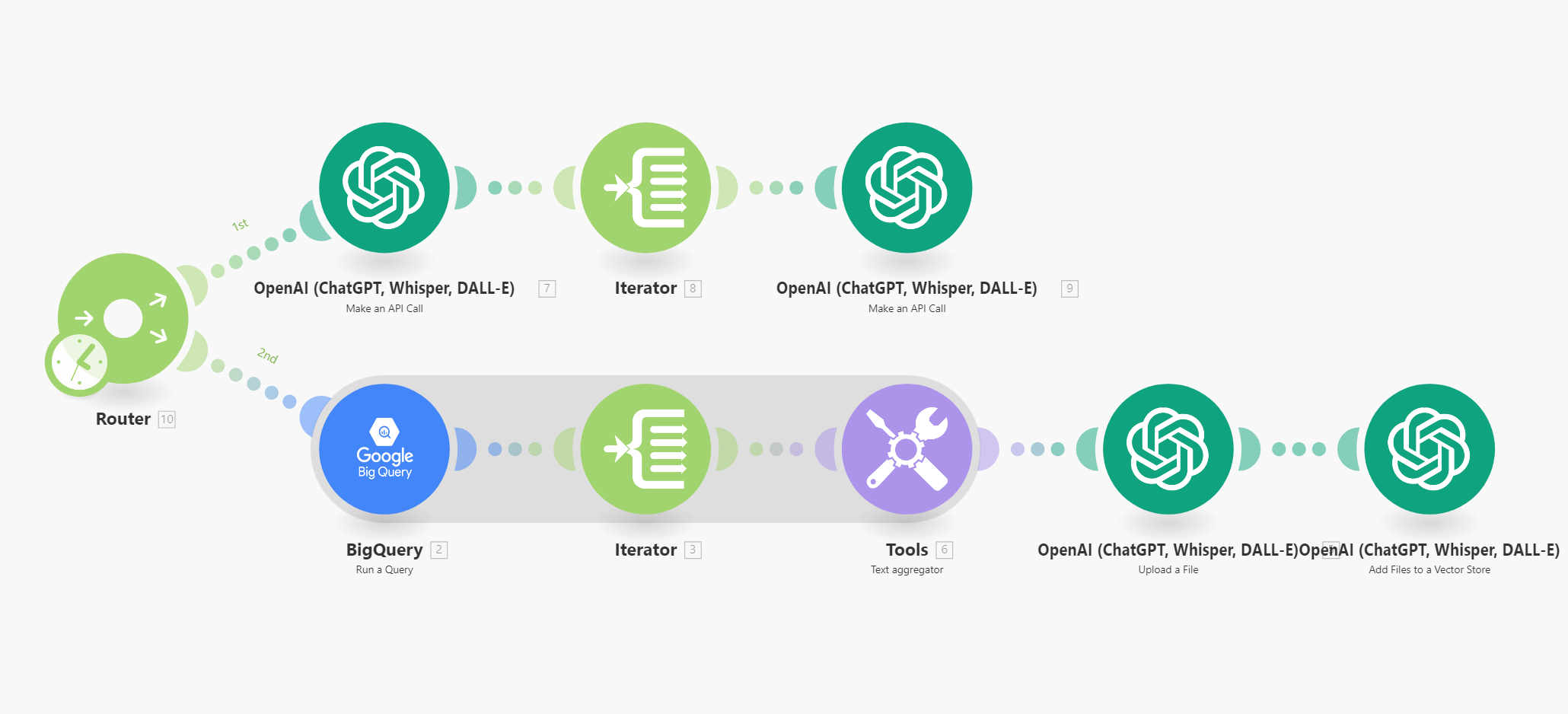
In the scenario above, you can see the first I delete the previous files from the vector store (I only need the latest snapshot of car models) and then I run a BigQuery query to retrieve all know car models and upload them as a new file to my vector store in OpenAI. Here you might be questioning how I am getting the car models from NHTSA to BigQuery – the answer is simple, it’s an ETL job done by a custom piece of code running outside Make since the NHTSA’s file are usually to big for Make scenarios.
Conclusion
Previously, to perform a quick analysis for one car model took roughly 15-30 minutes. Now it takes about 1-2 minutes for the Make scenario to run. Are the results perfect every single time? No, I’d say they are 90% accurate which is good enough for this use case.
Are you facing similar challenges?
HIRE ME
Or maybe you want to try yourself?
GO TO MAKE